
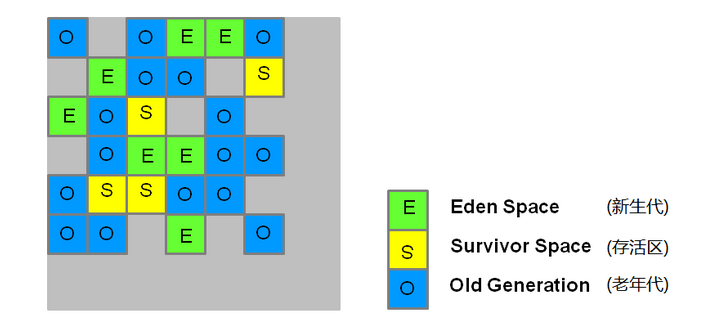
g1 收集器的 fullGC 和youngGC (都只是分区,而没有新生代和老年代的区别的话, 那还分这两种GC方式么?)
分, g1 收集器,对内存虽然不像CMS一样将内存分为 新生代,老年代,和永久代, 而是将内存分为多个大小相等的区域,但是也会将不同的内存区域划分为不同代. 以下图片出处:传送门
软引用 引发的youngGC 和 fullGC 谁更先发生?
必然是 youngGC 回收软引用指向的对象先发生, fullGC只在youngGC无法满足内存需求时,才会发生.
MQ中pull和push的差别
| push模式 | pull模式 | |
|---|---|---|
| 描述 | 服务端主动发送数据给客户端 | 客户端主动从服务端拉去数据,通常客户端会定时拉取 |
| 实时性 | 较好,收到数据后可立即发送给客户端 | 一般,取决于pull的间隔时间 |
| 服务端状态 | 需要保存push状态,哪些客户端以及发送成功,哪些发送失败 | 服务端无状态(不用保存消息拉取状态什么的?那如何保证消息一定被consumer消费了?) |
| 客户端状态 | 无需额外保存状态 | 需保存当前拉取的信息状态,以便在故障或者重启的时候恢复 |
| 状态保存 | 集中式,集中在服务端 | 分布式,分散在各个客户端 |
| 负载均衡 | 服务端统一处理和控制 | 客户端之间做分配, 需要协调机制,如使用zookeeper |
| 其他 | 服务端需要做流量控制,无法最大话客户端的处理能力.其次,客户端故障的情况下,无效的push对服务端有一定负载(这个可以通过healthcheck来做,若consumer已挂,则不再push) | 客户端的请求可能有很多无效或者没有数据可供传输,浪费带宽和服务器处理能力 |
| 确定方案 | 服务端状态存储是个难点,可将这些状态转移到DB或者key-value存储,来减轻server压力 | 针对实时性的问题,可以将push加入进来,push小鼠据的通知信息,让客户端再开主动pull(服务端告诉客户端想在有多少消息,consumer根据自己的能力主动pull消息).针对无效请求的问题,可以设置逐渐延长间隔时间的策略,以及合理设计协议尽量缩晓请求数据包来节省带宽. |
差异:
- 实时性,push比pull的实时性更好.
- pull的无效拉取浪费服务端资源.
一些MQ的对比博文:
http://blog.csdn.net/sunxinhere/article/details/7968886
http://www.fattiger.com.cn/2016/03/14/mq-compare/
http://www.th7.cn/Program/Ruby/201604/796433.shtml
匿名类的一个使用特性
由于匿名类的实例,在刚刚new出来的时候,编辑器(javac)是知道它的实际类型的,所以匿名类增加了基类没有的方法的情况下,也是能够正常调用的.例如:
// 匿名类中增加了基类的没有的方法,依然可以在刚new出来的时候调用.
new Object(){
boolean foo() {
System.out.println("foo");
return false;
}
}.foo()
dubbo配置是如何解析的
例如 <dubbo:consumer/> 这个配置,Spring在加载配置文件的时候是怎么解析它的?
这是由 Spring提供的可扩展Schema支持 来解决的.
在xml配置文件中通常有如下内容:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://code.alibabatech.com/schema/dubbo
http://code.alibabatech.com/schema/dubbo/dubbo.xsd
">
并且在dubbo的包下面的 META-INFO/spring.handlers 中有以下内容:
http://code.alibabatech.com/schema/dubbo=com.alibaba.dubbo.config.spring.schema.DubboNamespaceHandler
在dubbo的包下面的 META-INFO/spring.schemas 中有以下内容:
http://code.alibabatech.com/schema/dubbo/dubbo.xsd=META-INF/dubbo.xsd
而且Spring在解析xml文件前会自动加载 META-INFO/spring.handlers 和 META-INFO/spring.schemas 两个文件.从而 xml文件中的xmlns:dubbo=\"http://code.alibabatech.com/schema/dubbo\" 表示当遇到命名空间为 dubbo的元素应该使用com.alibaba.dubbo.config.spring.schema.DubboNamespaceHandler进行处理, 并且 xsi:schemaLocation中的配置http://code.alibabatech.com/schema/dubbo/dubbo.xsd指明了dubbo命名空间的元素信息
从而dubbo的整个解析入口就找到了.(参考:传送门)
在springMVC中未使用@RequstParam的参数是如何绑定到相同参数名的变量上的
在springMVC的使用中经常使用如下的写法,但是我们知道通过反射只能拿到方法updateInfo的所有参数对应的Class,而拿不到对应的参数名(name和password)的.那么这种情况下springMVC是如何将请求中的参数与方法参数进行绑定的呢? (在JDK8中,新增了参数信息类Parameter,可通过Method.getParameters()获取到,从而可得到参数对应的名称)
@RequstMapping("/test")
public void updateInfo(String name, String password){
// do something
}
查看参数处理适配器 RequestMappingHandlerAdapter 的代码可发现, 上面这种情况是由 RequestParamMethodArgumentResolver来处理的.这种情况下 会使用 MethedParameter中的parameterName作为参数名称进行匹配.
查阅后发现,在spring-core包中提供LocalVariableTableParameterNameDiscoverer来获取方法参数对应的名称.在其方法inspectClass()中可知,它会从类对应的 .class 文件中去获取方法参数名.(具体存放位置,可查看.class文件定义相关文章)
哈希表(散列表)解决冲突的方式
- 线性探测
- 多次哈希
- 链表
JVM正常关闭的时候,finally块在什么情况下会不执行
如果线程被设置为了守护线程,则其finally块并不一定会被执行
int.class 和 Integer.class 是否一样
不一样,虽然它们都是 Class<Integer>类型的,但是它们是两个不一样的类.一个代表的是java内置对象的class对象,一个是普通java类的class对象