
领域驱动设计(domain driven design)
模型是对现实有选择的精简
- 哪些对象是对我们的系统有用的?
- 哪些是对我们拟建系统没有用处的?
- 我们应该如何保证我们选取的 模型对象恰好够用?
什么是领域驱动设计?
即为了创建一个好的软件,你必须知道你这个软件究竟是什么,在你充分了解一个领域的业务知识之前,你是做不出一个好的软件的,你必须了解这些业务对应的领域。
软件设计中常用的两种设计方法:
- 瀑布设计方法 (知识单一的流向,它有它的缺点和局限,上游人员得不到下游人员的反馈,业务专家得不到分析员的反馈,分析员的不到开发人员的反馈)
- 敏捷方法学 (试图解决 分析瘫痪 问题,反对预先设计,通过不断的迭代和重构来进行开发,缺点和局限:每个开发都有自己的观点,缺乏简单可见的原则,多次的重构使得代码难以理解和维护)
我们要如何来做?
-
建模,我们需要用模型来交流,我们对领域所有的思考都汇集到这个模型中来。 1.1 构建领域知识:通过和业务专家的不断的沟通讨论,了解需求的业务 1.2 使用通用语言:使用大家都能理解的通用语言,便于沟通和表达
-
抽取 模型驱动设计的基本构成要素(下图展示构成的基本要素)
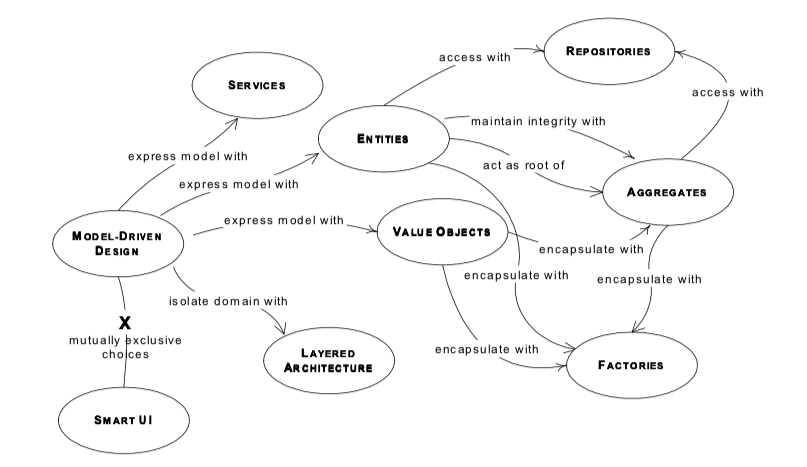
2.1 分层: 用户界面(User Interface) - 应用层(Application) - 领域层(Domain) - 基础设施层(Infrastracture) 2.2 元素抽取: 实体(包含实体标识符),值对象(相对于试图对象来说,它没有标识符),服务,模块
- 持续重构 3.1 重构应该使得关键概念更加凸显 3.2 保持模型一致性(多个团队共同保持) 3.2.1 界定的上下文(多个团建间) 3.2.2 持续集成(上下文界定后,通过,创建测试集保证上下文的界定,并将模型新的元素持续集成进对应的模型) 3.2.3 上下文映射(Context Map),是指抽象出不同界定上下文和它们之间关系的文档,它可以是像一个试图(Diagram),也可以是其他任何写就的文档。详细的层次各有不同。它的重要之处是让每个在项 目中工作的人都能够得到并理解它。 3.2.4 共享内核: 多个团队的模型间共享一部分,这是为了减少重复性劳动,同时也增加了维护的工作量,对共享内核的开发要更加小心 3.2.5 客户-供应商:一个团队严重依赖另一个,依赖方(客户)就需要以提需求的方式对被依赖方(供应商)获取所需要的功能,这是在两个团队有兴趣合作时。 3.2.6 顺从者:当两个团队没法以 客户-供应商 的方式合作时,依赖方就只能顺从被依赖方的模型,当时它无法修改模型的核心,只能读取(这是和共享内核的区别) 3.2.7 防奔溃层:如果新模型和老模型不兼容,但我们必须将两个模型分别开来,不能让老模型影响新模型,则可以使用一个Facede模式和Adapter模型在新老模型之间做一个适配。 3.2.8 独立方法:独立方法模式适合一个企业应用可由几个较小的应用组成,而且从 建模的角度来看彼此之间有很少或者没有相同之处的情况。它有一 套自己的需求,从用户角度看这是一个应用,但是从建模和设计的 观点来看,它可以由有独立实现的独立模型来完成。 3.2.9 开放主机服务:定义一个能以服务的形式访问你子系统的协议。开放它,使得所有 需要和你集成的人都能获取到。然后优化和扩展这个协议,使其可 以处理新的集成需求,但某团队有特殊需求时除外。对于特殊的需 求,使用一个一次性的转换器增加协议,从而使得共享的协议保持 简洁和精干。 3.2.10 精炼:精炼是从一个混合物中分离物质的过程。精炼的目的是从混合物中 提取某种特殊的物质。在精炼的过程中,可能会得到某些副产品, 它们也是很有价值的。精炼模型。找到核心域,发现一个能轻松地从支持模型和代码中区 分核心域的方法。强调最有价值和特殊的概念。使核心变小
模块划分
- 通讯性内聚:常在模块的部件操作相同的数据时使用。把它们分到一组很有意义,因为它们之间存在 很强的关联性
- 功能性内聚
三种模块化设计:
- 聚合
- 工厂
- 资源库
聚合
对模型中的关系进行消减和简化,使其尽量简单和容易理解
将多个实例或值对象 聚合 为一个根实体,根实体拥有全局的标识符,并且有责任管理不变量。内部的实体拥 有内部的标识符
工厂
如果对聚合对象的构造器方法过于复杂,那么在构建这个对象是,客户端需要知道构建此对象的复杂专业知识,这样也就破坏了领域对象和聚合的封装。 所以需要一个新的概念来帮助封装复杂的对象创建过程,即:工厂,使用工厂来封装对复杂聚合对象所必须的知识,对创建聚合对象特别有用。个聚合当作一个单元来创 建,强化它们的不变量。(工厂方法和抽象工厂)
适合直接使用构造器而无需使用工厂的情况:
- 构造过程并不复杂。
- 对象的创建不涉及到其他对象的创建,所有的属性需要传递给构造函数。
- 客户程序对实现很感兴趣,可能希望选择使用策略模式。
- 类是特定的类型,不涉及到继承,所以不用在一系列的 具体实现中进行选择。
资源库
使用一个资源库,它的目的是封装所有获取对象引用所需的 逻辑。领域对象不需处理基础设施,以得到领域中对其他对象的所 需的引用。只需从资源库中获取它们,于是模型重获它应有的清晰 和焦点。
工厂关注的 是对象的创建,而资源库关心的是已经存在的对象。资源库可能会 在本地缓存对象,但更常见的情况是需要从一个持久化存储中检索 它们。
面向深层次理解的重构
持续重构
我们被教教授的关于建模的第一件事是阅读业务规范,从中寻找名 词和动词。名词被转换成类,而动词则成为方法。
善于查找 隐形概念,让隐形概念显示化,
使用规约
用来测试一个对象是否满足特定的条件,同样也是一种将概念显示化的方法
保持模型一致性
在若干个团队通力合作配合的大项目中,要使各个团队基于一个统一的模型进行开发,是不容易实现的,统一的企业模型是不容易实现的理想状态
保存模型一致性的方法:
- 界定的上下文
每一个模型都有一个上下文,一个独立模型的上下文都是固定的 ,当开发大的企业应用时,需要为每一个创建的模型定义上下文, 模型的切分,应该尽量把相关联的以及能形成一个自然概念的因素放在一个模型中,模型应该足够小,以便能分给一个团队去实现。 定义模型范围,画出它的上下文边界。界定的上下文提供有模型参与的逻辑框架。模块被用来组织模型的要素,因此界定的上下文包含模块。 们需要确保模型的纯洁、一致和完 整。
- 持续集成
模型不是一开始就被完全定义,先是被创建,然后基于对领域模型的发现和开发时的反馈等再继续完善。所有这些都需要被集成进一个统一的模型,这就是为啥持续集成在界定上下文中如此必要的原因。
持续集成是基于模型中概念的集成,然后再通过测试实现。
- 上下文的映射
创建上下文映射的模式:
- 共享内核 :共享领域模型子集,减少重复,但是仍然保持两个独立的上下文
- 客户-供应商:客户团队提出需求,供应商团队讨论需求,并实现
- 顺从者:如果上面的 客户-供应商 关系中,供应商没有时间和精力去实现客户的需求,那么客户就只能顺从供应商的,客户团队遵从供应商团队的模型,完全顺从它,(顺从者模式和共享内核模型的差别是,客户不能修改内核模型,只能用它作为自己模型的一部分。)
- 防奔溃层:利用门面模式和适配器模式,处理新应用和遗留软件应用之间的相互交互问题。
- 独立方法:独立方法模式适合一个企业应用可由几个较小的应用组成,而且从 建模的角度来看彼此之间有很少或者没有相同之处的情况。它有一 套自己的需求,从用户角度看这是一个应用,但是从建模和设计的 观点来看,它可以由有独立实现的独立模型来完成。
- 开放主机服务:定义一个能以服务的形式访问你子系统的协议。开放它,使得所有 需要和你集成的人都能获取到。然后优化和扩展这个协议,使其可 以处理新的集成需求,但某团队有特殊需求时除外。对于特殊的需 求,使用一个一次性的转换器增加协议,从而使得共享的协议保持简洁和精干。(用来处理集成多个子系统的情况)
- 精炼:思路是定义一个代表领域本质的核心域( Core Domain)。精炼过程的副产品将是组合领域中其他部分的普通子域 (Generic Subdomain),精炼使得模型的本质更加清晰。在之前的空中监控系统中,据已有的数据同 步飞机轨道的模块才是这个业务系统的 “心脏”,可以将它标识为 核心域。而非线路模型。路线模型更像是一个普通域。
- 隔离通道