
问题描述
新项目使用 spring cloud feign 作为远程服务调用框架,并在项目中添加了如下的ribbon重试配置:
ribbon:
ReadTimeout: 5000
ConnectTimeout: 5000
MaxConnectionsPerHost: 300
MaxTotalConnections: 2000
MaxAutoRetries: 0
MaxAutoRetriesNextServer: 3
httpclient:
enabled: true
但是在项目上线后,在正常的发布过程中,即使server端是一台一台的部署的,但是在client端依然会报错,并请求失败。
排查结果
spring-cloud-netflix-core中会使用RibbonLoadBalancedRetryPolicy作为重试策略,在 org.springframework.cloud.netflix.ribbon.RibbonLoadBalancedRetryPolicy#canRetry 可以看到如下代码:
public boolean canRetry(LoadBalancedRetryContext context) {
HttpMethod method = context.getRequest().getMethod();
return HttpMethod.GET == method || lbContext.isOkToRetryOnAllOperations();
}
即:只有在请求是 GET 或者 OkToRetryOnAllOperations 为true时会重试,而 OkToRetryOnAllOperations 默认是false,所以client端所有的post请求在发生 connection refuse 的时候并不会再进行重试。解决方案是将 OkToRetryOnAllOperations 设置为 true 即可。
ribbon:
OkToRetryOnAllOperations: true
需要注意的是这样设置之后所有的方法都会进行重试,server端需要保证接口的幂等性,例如发生 read timeout 时,若接口不是幂等的,则可能会造成脏数据。
排查过程
出现这个问题,首先就想到了可能是重试没有生效,于是写了一个demo和项目中的配置保持一致,在server端直接抛出了一个异常来验证(这个地方使用的是GET)。结果发现重试真的没有触发。确认是这个问题了,然后就开始在本地单步调试,去确认原因:
单步调试,跟进远程方法调用,发现实际调用的是 feign.ReflectiveFeign.FeignInvocationHandler#invoke,即feign使用JDK的动态代码生成了代理对象,根据调用的方法,选择远程http接口进行调用:
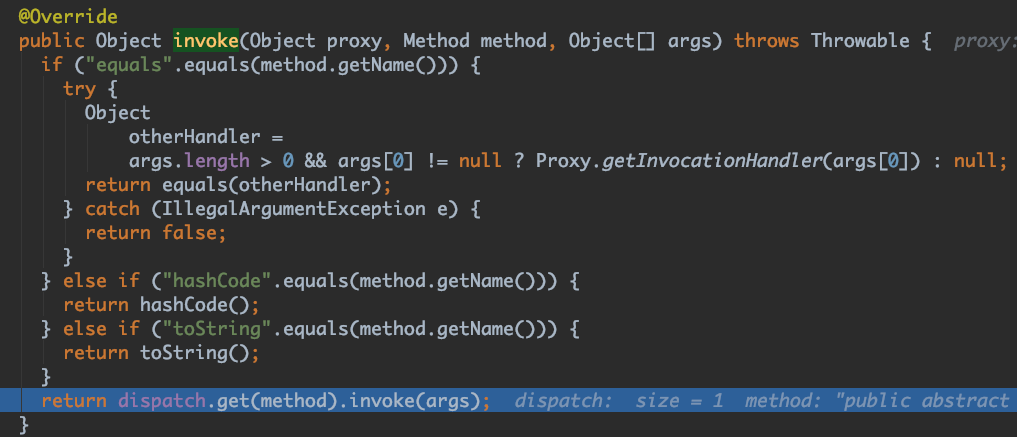
继续进去,你会发现到了 feign.SynchronousMethodHandler#invoke, 在这里你会发现一个retryer,不过这里的retryer是 feign.Retryer#NEVER_RETRY 即不重试 (这里是因为ribbon已经有重试了,如果再加入feign的重试,会有多次重试问题,所以spring cloud中就将其设置为了NEVER_RETRY).
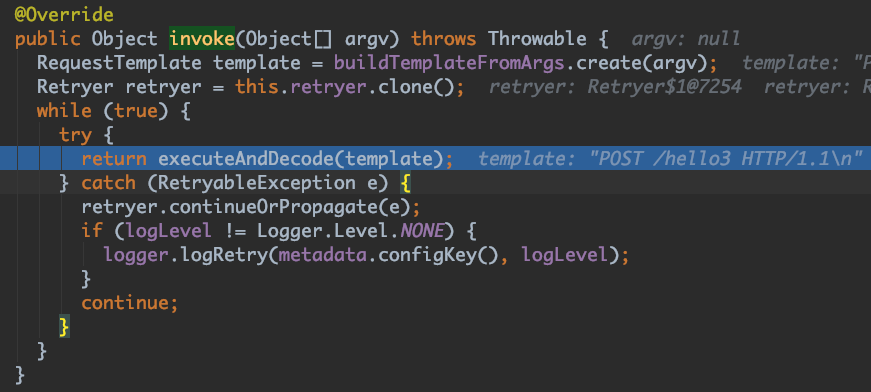
进入 executeAndDecode(), 接下来,feign会使用Client进行调用,这里是 org.springframework.cloud.netflix.feign.ribbon.LoadBalancerFeignClient, 继续往下, LoadBalancerFeignClient 中根据服务应用名选择对应的负载均衡客户端进行调用:
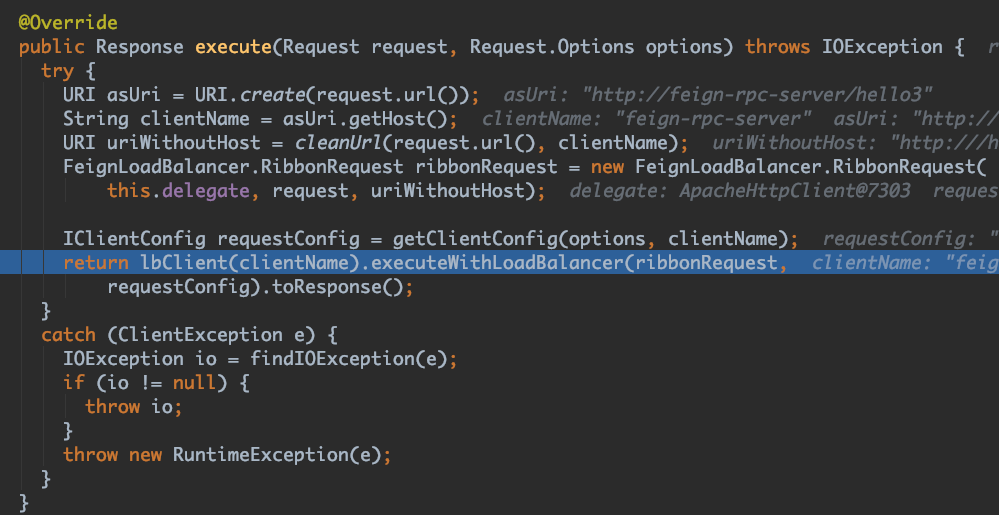
进入 executeWithLoadBalancer() 方法,到了 com.netflix.client.AbstractLoadBalancerAwareClient,而根据this引用可以发现这是个 org.springframework.cloud.netflix.feign.ribbon.RetryableFeignLoadBalancer的实例:
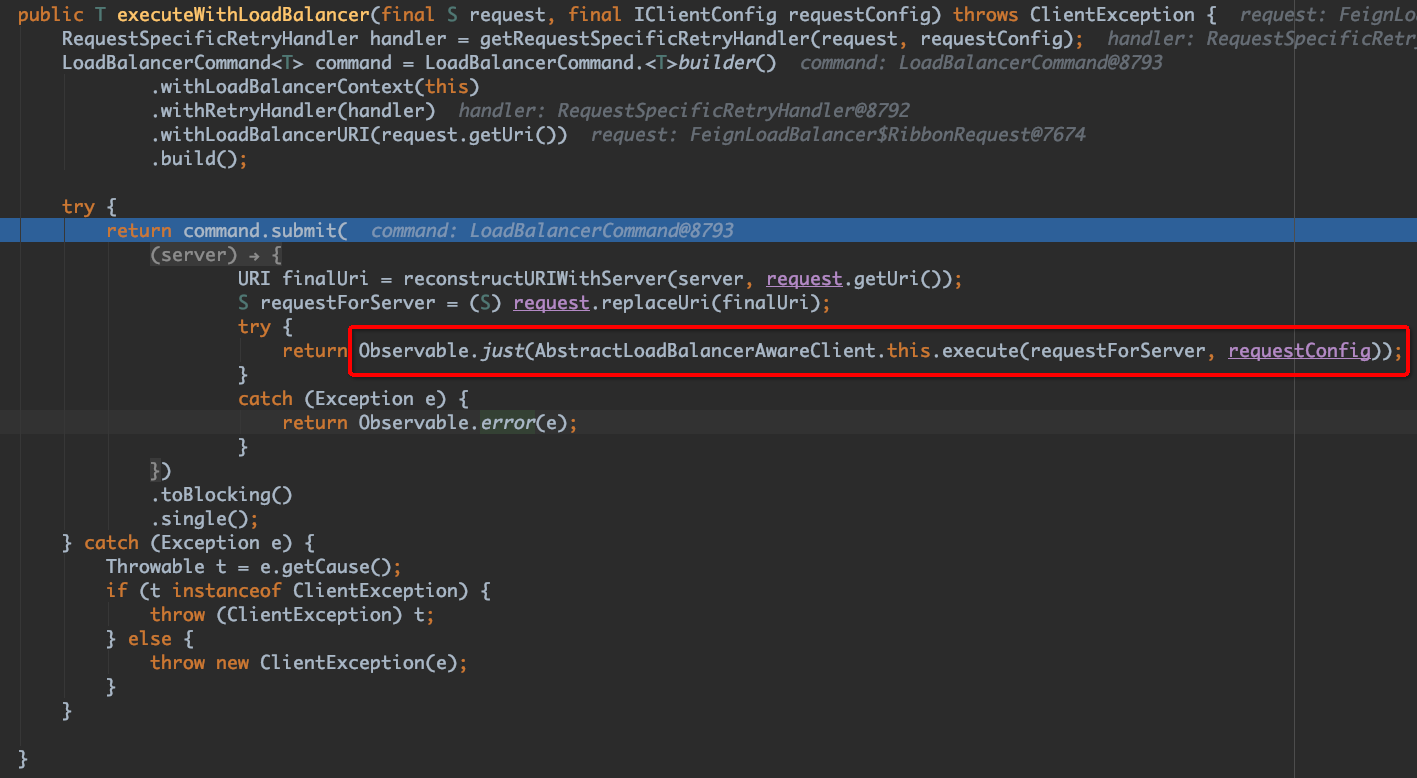
这里需要注意的是这个execute方法的调用,在这里实际也就是 RetryableFeignLoadBalancer#execute 方法的调用。
继续进入 commond.submit(),这里为了方便,把不重要的代码收来了:
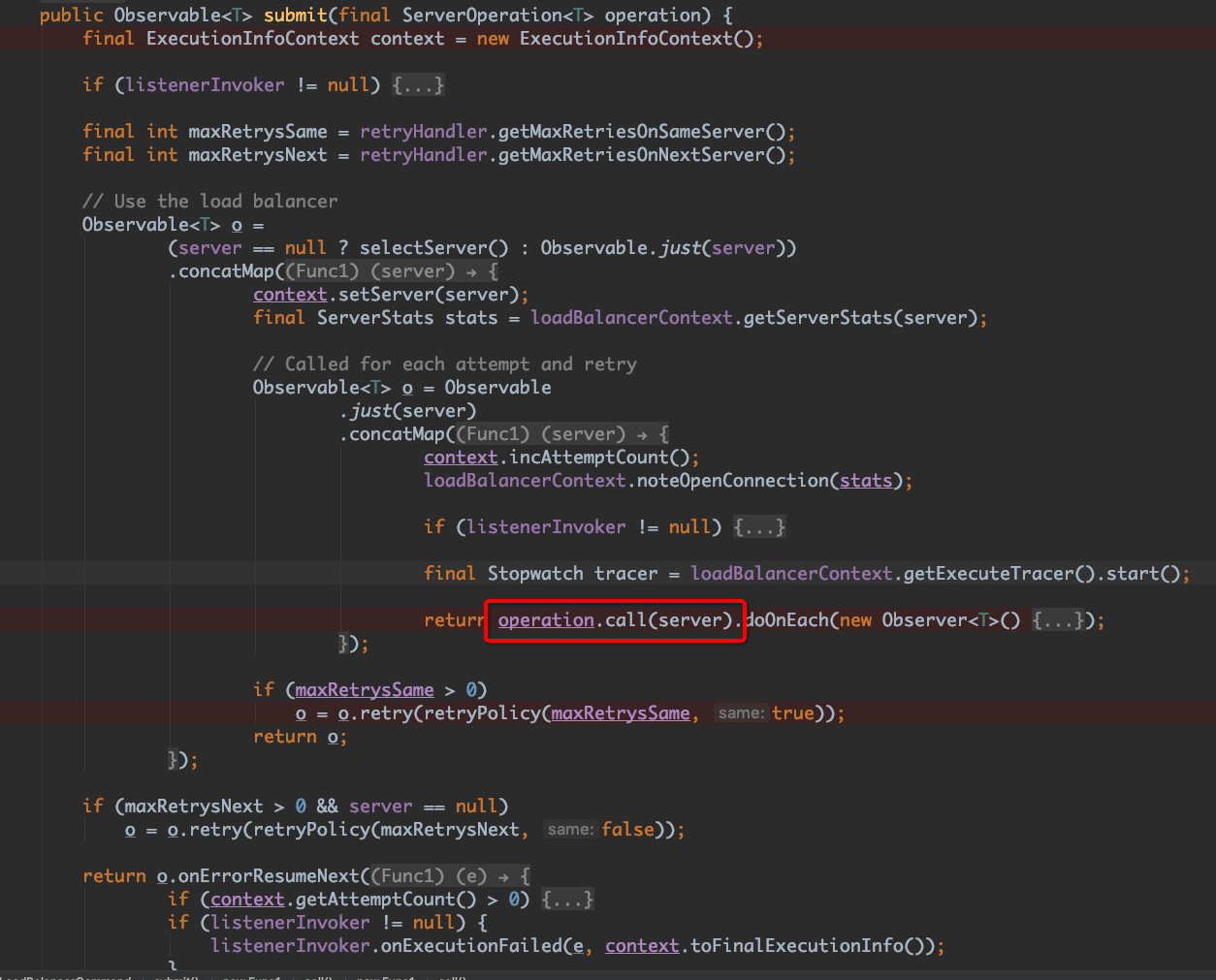
这里有很重要的一点,在 commond.submit() 中你会发现里面有重试相关的代码,对被观察的对象设置了其重试策略,并且使用到的配置也是我们在 一开始配置的 MaxAutoRetries 和 MaxAutoRetriesNextServer,但是如果你在其重试策略中打断点,你会发现代码根本无论如何都走不到这里,这是因为ribbon使用的rxJava这个观察者模式框架,在被观察者的调用过程中,如果不抛出异常,是不会触发它的重试的,而上面这里,也就是 operation.call(server) 这个地方,如果不抛出异常,其实submit中设置的重试永远也不会发生。而再回到 AbstractLoadBalancerAwareClient 中看,提交的任务逻辑里是 catch 了 Excetion 的。所以我们真正要看的逻辑实在 RetryableFeignLoadBalancer#execute 中:
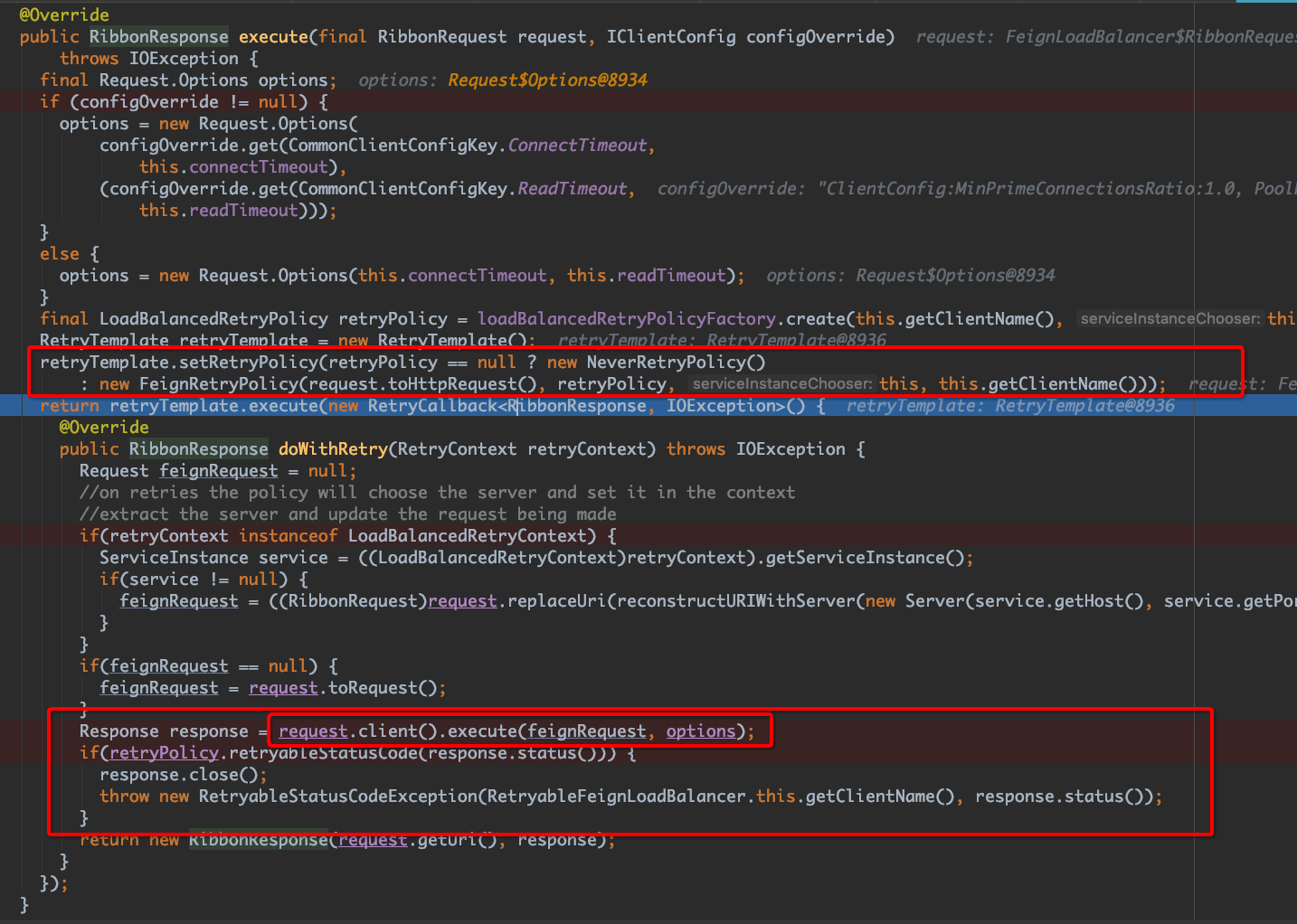
而这里可以看到实际用的是 spring-retry 中的 TetryTemplate 做重试,这也就是为啥spring-cloud文档中说的重试是依赖于spring-retry的原因了。第一个圈出来的位置是在设置重试策略, 第二个大圈的地方,你会发现,调用了execute之后,判断了是否是需要重试的http状态码,如果是才会重试,如果不是,则直接返回了。
你会发现我demo里写的那种直接在server端抛出一个异常的方式是不行的,这种情况下,其实并不算是异常,其实是server端正常返回了,而返回的结果是status=500而已,所以我修改了demo的代码,将server端的逻辑修改为 sleep 7秒(我在client端设置的超时时间是5s),再重新执行,发现重试居然成功被触发了。
再回过头来重新分析一下问题,server只重启了一台机器,client端也会报错,这肯定是重试没生效啊,如果生效了怎么可能会报错啊。最后再看报错的那些异常,突然发现报错的居然全是post请求,难道是post请求不会重试?所以我又将方法请求改为了post,再次运行demo,发现真的居然没有重试了。既然问题重现了,那我继续单步调试看看,断点打在 上面的 retryTemplate.execute(), 进去看看:
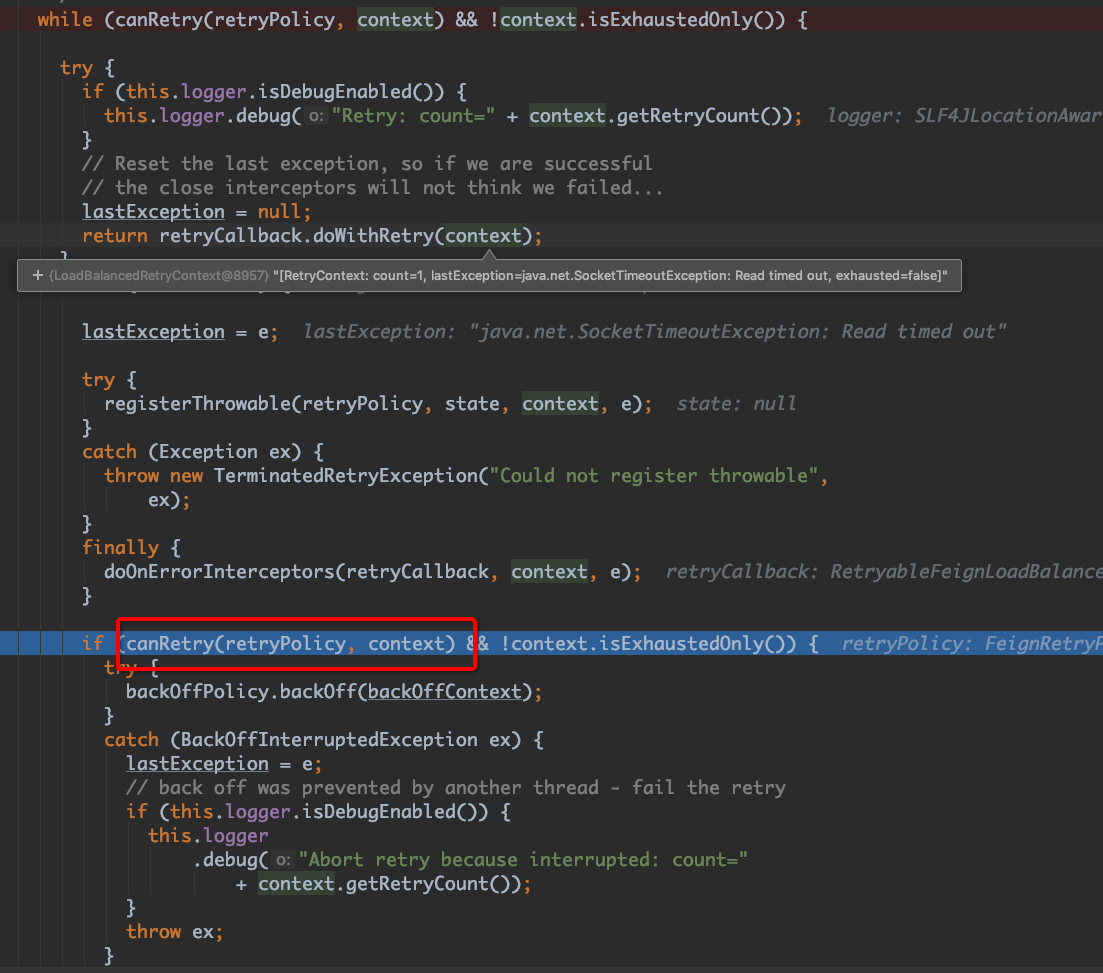
当client端超时异常时,程序会走到这里。继续往里面跟进,会走到 RibbonLoadBalancedRetryPolicy 中的:

继续跟进canRetry会发现如下代码:

真相终于大白:只有在请求是 GET 或者 OkToRetryOnAllOperations 为true时会重试,而 OkToRetryOnAllOperations 默认是false,所以client端所有的post请求在发生 connection refuse 或者 read timeout 的时候并不会再进行重试。
其他
- ribbon配置类:org.springframework.cloud.netflix.ribbon.RibbonAutoConfiguration
- feign负载配置类: org.springframework.cloud.netflix.feign.ribbon.FeignRibbonClientAutoConfiguration